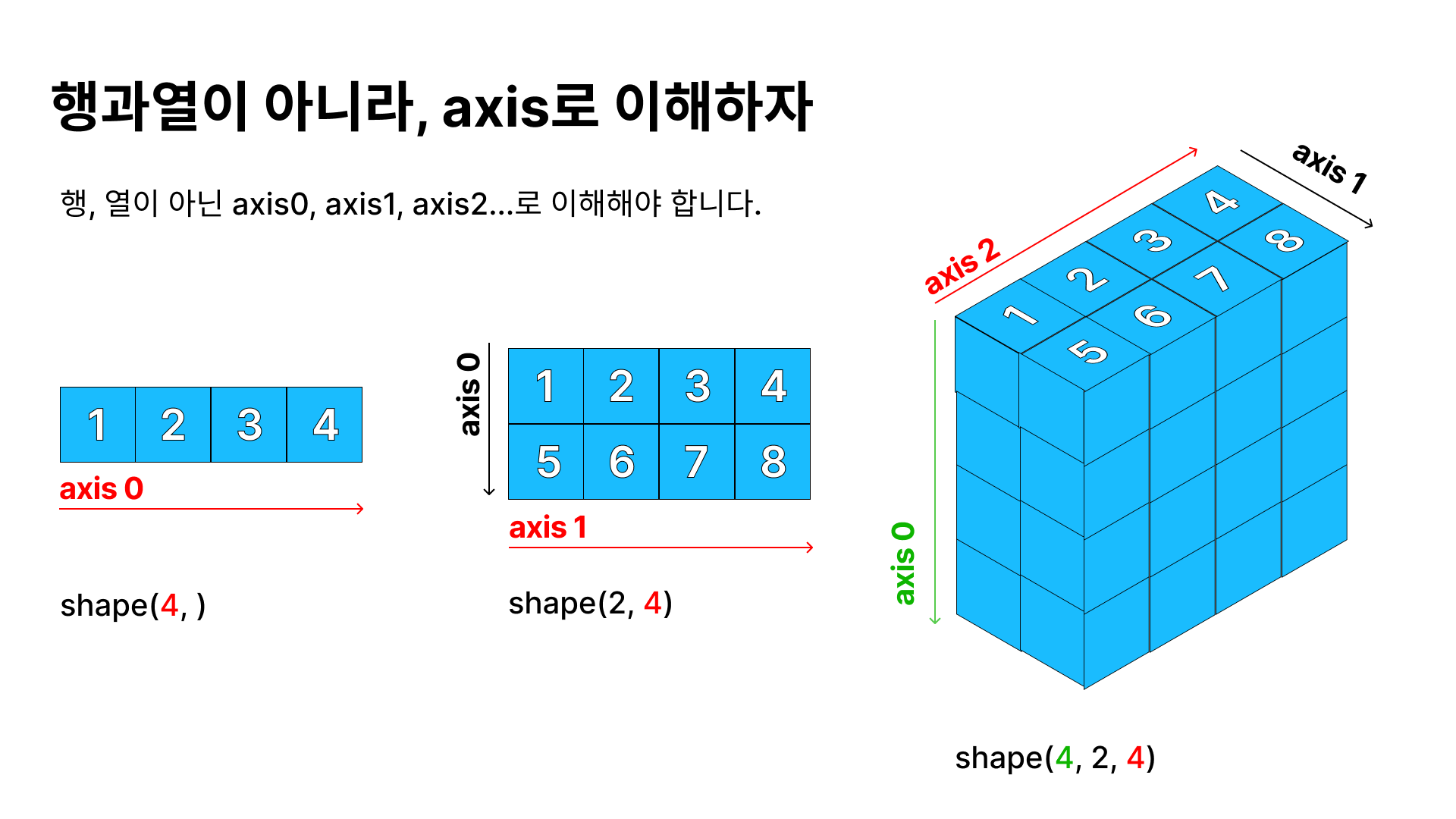
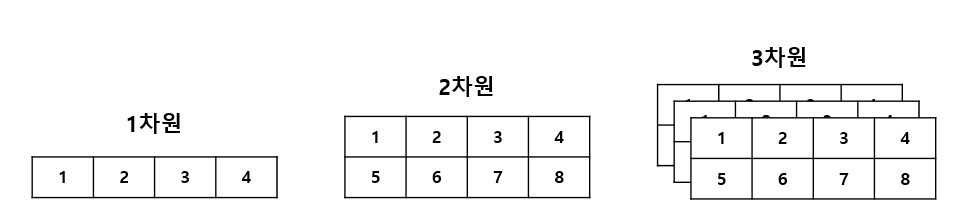
파이썬에서 numpy와 pandas를 공부하다 보면 다차원의 배열을 접하게 되고, 이 과정에서 다양한 함수를 사용하게 되는데요. 이때 axis(축)에 대해서 접하게 됩니다. 다른 분들의 글을 읽어보아도 대다수의 분들이 입문~초보자의 수준에서 공부하게 될 때는, 3차원까지만 알아도 수월하게 공부할 수는 있다고 합니다. 그렇지만, 그래도 공부할 거 이왕이면 중급자는 목표로 해야죠. (혼자 공부하는 데 고수까지는 바라지도 않습니다?) 네, 일단 4차원은 어떻게 그리는지 모르겠어서 3차원 까지만 그렸습니다. 파이썬의 배열은 리스트가 겹겹이 쌓여 중첩된 것입니다. 1차원 배열은 축이 1개, 2차원 배열은 축이 2개, 3차원 배열은 축이 3개입니다. 축은 인덱스와 마찬가지로 1부터 시작하는 게 아니라, 0부터 시작..