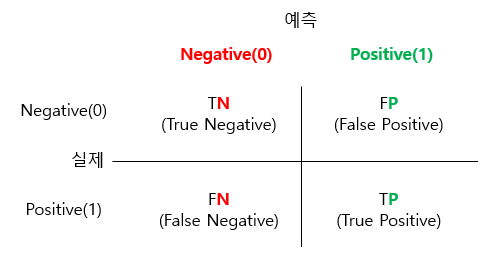
빅데이터분석기사 실기 시험을 위해 필요한 공부만 하고 정리도 할 겸 올리는 MinMaxScaler. 정확한 정보를 원하시면 공식 문서를 참고하는 게 좋습니다. 응시환경 체험하기 작업형 제1 ,2 유형을 기반으로 정리해 보았습니다. https://www.dataq.or.kr/www/board/view.do?bbsKey=eyJiYnNhdHRyU2VxIjoxLCJiYnNTZXEiOjUwOTM0M30=&boardKind=notice 데이터자격시험 www.dataq.or.kr # Min-Max Scale 방법 1 import pandas as pd from sklearn.preprocessing import MinMaxScaler df = pd.read_csv('data/mtcars.csv', index_co..