Numpy는 같은 종류의 데이터 타입으로 이루어져 있는 다차원 배열 타입인 ndarray를 제공합니다. '같은 종류의 데이터 타입'이라는 것은 한 개의 ndarray 객체 내에서 int와 float가 공존할 수 없다는 뜻입니다. 파이썬의 리스트는 하나의 리스트 객체에 int, float, string 등을 모두 공존할 수 있습니다만, ndarray에서는 허용하지 않습니다.
ndarray를 생성하기 위해서 ndarray()라는 함수를 사용할 수도 있습니다만, 권장되지는 않습니다. 실제로 공식 문서에도 ndarray대신 array, zeros 혹은 empty 등의 함수를 사용해서 생성하라고 적혀있습니다.
Arrays should be constructed using array, zeros or empty (refer to the See Also section below). The parameters given here refer to a low-level method (ndarray(…)) for instantiating an array.
* 참고 : numpy 공식문서
1. ndarray 생성하기
numpy 공식문서에서 언급한 것처럼 ndarray가 아닌 다른 함수들을 사용해서 ndarray를 편리하게 생성해 보겠습니다.
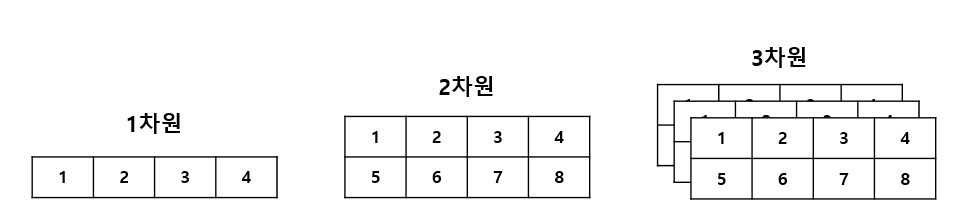
1) array()
우선, array() 함수입니다. array_like 객체를 인자로 넣으면 해당 객체를 ndarray로 반환하는 함수인데요. array_like는 파이썬의 리스트, 튜플과 같이 것이라고 생각하면 될 것 같습니다.
import numpy as np
array1D = np.array([1, 2, 3, 4])
array2D = np.array([[1, 2, 3, 4],
[5, 6, 7, 8]])
array3D = np.array([[[1, 2, 3, 4],
[5, 6, 7, 8]],
[[9, 10, 11, 12],
[13, 14, 15, 16]]])
print(array1D)
print('array1D의 shape:', array1D.shape)
print(array2D)
print('array2D의 shape:', array2D.shape)
print(array3D)
print('array3D의 shape:', array3D.shape)[출력]
[1 2 3 4]
array1D의 shape: (4,)
[[1 2 3 4]
[5 6 7 8]]
array2D의 shape: (2, 4)
[[[ 1 2 3 4]
[ 5 6 7 8]]
[[ 9 10 11 12]
[13 14 15 16]]]
array3D의 shape: (2, 2, 4)ndarray의 shape 속성은 ndarray의 행과 열의 수를 튜플 형태로 반환해 주는데, 결과 값을 통해 배열의 차원까지 알 수 있습니다. [1,2,3,4]인 array1D의 shape는 (4,)인데, 이는 1차원 array를 나타내는 것으로 4개의 데이터를 가지고 있음을 알 수 있습니다. array2D는 (2, 4)인데, 이는 2차원 array를 나타내는 것으로 2개의 행(row)과 4개의 열(column)로 이루어져 있음을 알 수 있습니다. 마지막으로 array3D는 (2, 2, 4)인데, 이는 3차원 array를 나타내는 것으로 2개의 행과 4개의 열로 이루어져 있는 2차원 배열 2개로 이루어져 있음을 알 수 있습니다.
2) zeros()
함수의 인자로 위에서 다룬 shape처럼 튜플을 전달해 주면 이름에서 알 수 있듯이 0으로 채워진 ndarray객체를 반환합니다. default dtype(데이터타입) 값은 float입니다. dtype을 별도로 지정하지 않으면 float 형태로 ndarray를 채웁니다.
array_zero = np.zeros((2, 4))
array_zero_int = np.zeros((2, 4), dtype='int')
print(array_zero)
print('array_zero의 shape 및 데이터 타입:', array_zero.shape, array_zero.dtype)
print(array_zero_int)
print('array_zero_int의 shape 및 데이터 타입:', array_zero_int.shape, array_zero_int.dtype)[출력]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]]
array_zero의 shape 및 데이터 타입: (2, 4) float64
[[0 0 0 0]
[0 0 0 0]]
array_zero_int의 shape 및 데이터 타입: (2, 4) int643) ones()
zeros()와 마찬가지로, 함수의 인자로 위에서 다룬 shape처럼 튜플을 전달해 줍니다. 이름에서 알 수 있듯이 1로 채워진 ndarray객체를 반환합니다. default dtype(데이터타입) 값은 float입니다. dtype을 별도로 지정하지 않으면 float 형태로 ndarray를 채웁니다.
array_one = np.ones((2, 4))
array_one_int = np.ones((2, 4), dtype='int')
print(array_one)
print('array_one의 shape 및 데이터 타입:', array_one.shape, array_one.dtype)
print(array_one_int)
print('array_one_int의 shape 및 데이터 타입:', array_one_int.shape, array_one_int.dtype)[출력]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]]
array_one의 shape 및 데이터 타입: (2, 4) float64
[[1 1 1 1]
[1 1 1 1]]
array_one_int의 shape 및 데이터 타입: (2, 4) int64
2. ndarray의 homogeneous
ndarray 객체 내의 값은 동일한 데이터 타입만 가능하다고 언급했습니다. int면 int, float면 float끼리만 있을 수 있습니다. 하지만 고의로 ndarray를 생성할 때 다른 데이터 타입을 넣게 되면 어떻게 될까요? 데이터 크기가 더 큰 데이터 타입으로 일괄 형 변환이 됩니다.
str_int_list = [1, 2, 3, 'list']
array1 = np.array(str_int_list)
print(array1, array1.dtype)
float_int_list = [1, 2, 3.0, 4.0]
array2 = np.array(float_int_list)
print(array2, array2.dtype)[출력]
['1' '2' '3' 'list'] <U21
[1. 2. 3. 4.] float64문자형과 int형이 섞여있는 str_int_list를 ndarray로 변환한 array1은 전부 문자열 값으로 변경되었습니다. (<U21은 유니코드 문자열을 뜻합니다.)
float형과 int형이 섞여있는 float_int_list를 ndarray로 변환한 array2는 전부 float형으로 변경되었습니다.
이처럼 데이터 타입이 섞여있을 경우 더 큰 데이터 타입으로 변경되는 것을 확인할 수 있습니다.
'공부 > 파이썬(데이터)' 카테고리의 다른 글
| [파이썬] numpy, pandas에서의 axis 이해하기 (1) | 2023.11.12 |
|---|---|
| [파이썬 sklearn] 빅데이터분석기사 1유형 예시 코드 - minmax 스케일링 (0) | 2023.10.14 |
| [파이썬 sklearn] train_test_split 학습, 테스트 데이터 나누기 (빅데이터분석기사) (0) | 2023.10.13 |
| [파이썬 sklearn] 오차행렬(혼동행렬, confusion matrix) 공부하기 - 평가 지표 이해(1) (1) | 2023.10.11 |